# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as so# statisticsimport statsmodels.api as sm# pandas optionspd.set_option('mode.copy_on_write', True) # pandas 2.0pd.options.display.float_format ='{:.2f}'.format# pd.reset_option('display.float_format')pd.options.display.max_rows =7# max number of rows to display# NumPy optionsnp.set_printoptions(precision =2, suppress=True) # suppress scientific notation# For high resolution displayimport matplotlib_inlinematplotlib_inline.backend_inline.set_matplotlib_formats("retina")
카테고리 변수에 대해서도 비슷하게 생각할 수 있음.
이 경우, 두 그룹 간의 차이에 대한 효과의 크기를 말할 수 있고, \(R^2\) 이외에도 Cohen’s d로 표현할 수 있음.
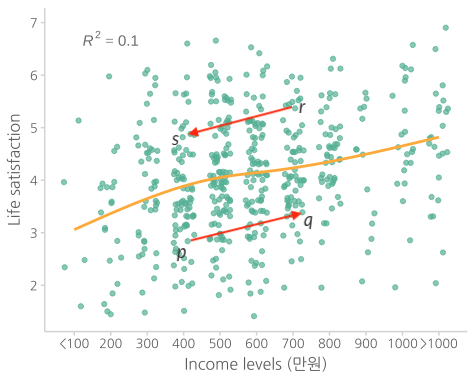
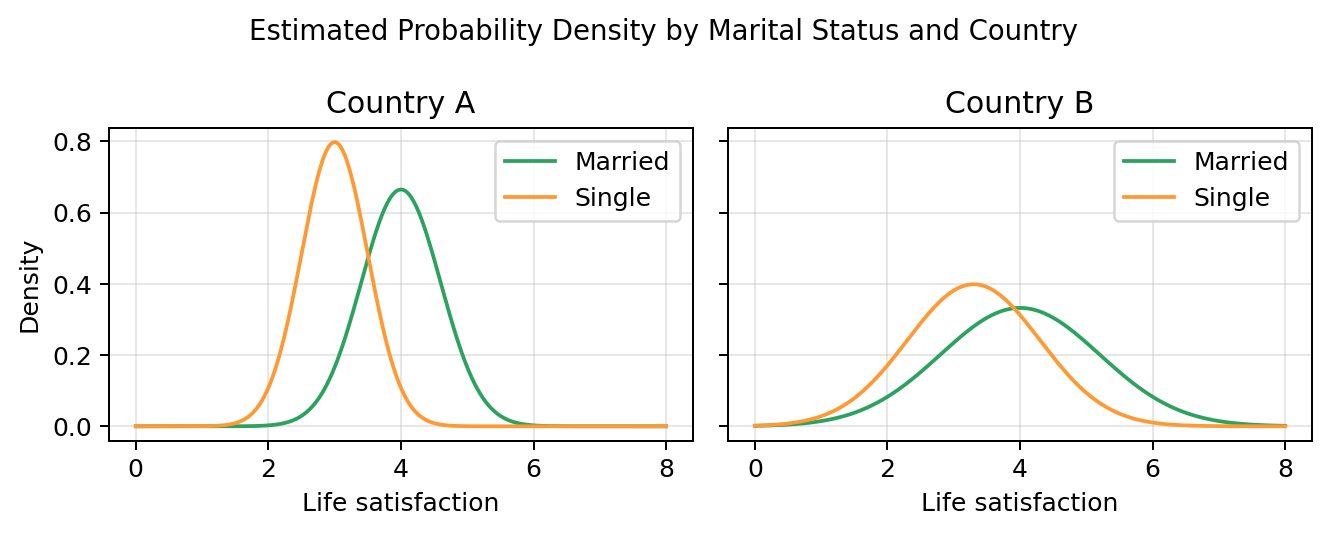
예를 들어, 결혼과 삶의 만족도 간의 관계(association)와 그 강도(strength)
Important
인과 관계에 대한 섯부른 추론은 금물!
특히, 예측력이 낮은 경우; Leo Breiman의 중요 요지 중 하나
Multiple Regression
예측변수가 2개 이상인 경우: 변수들 간의 진실한 관계를 분석; 인과관계 추론을 지향함
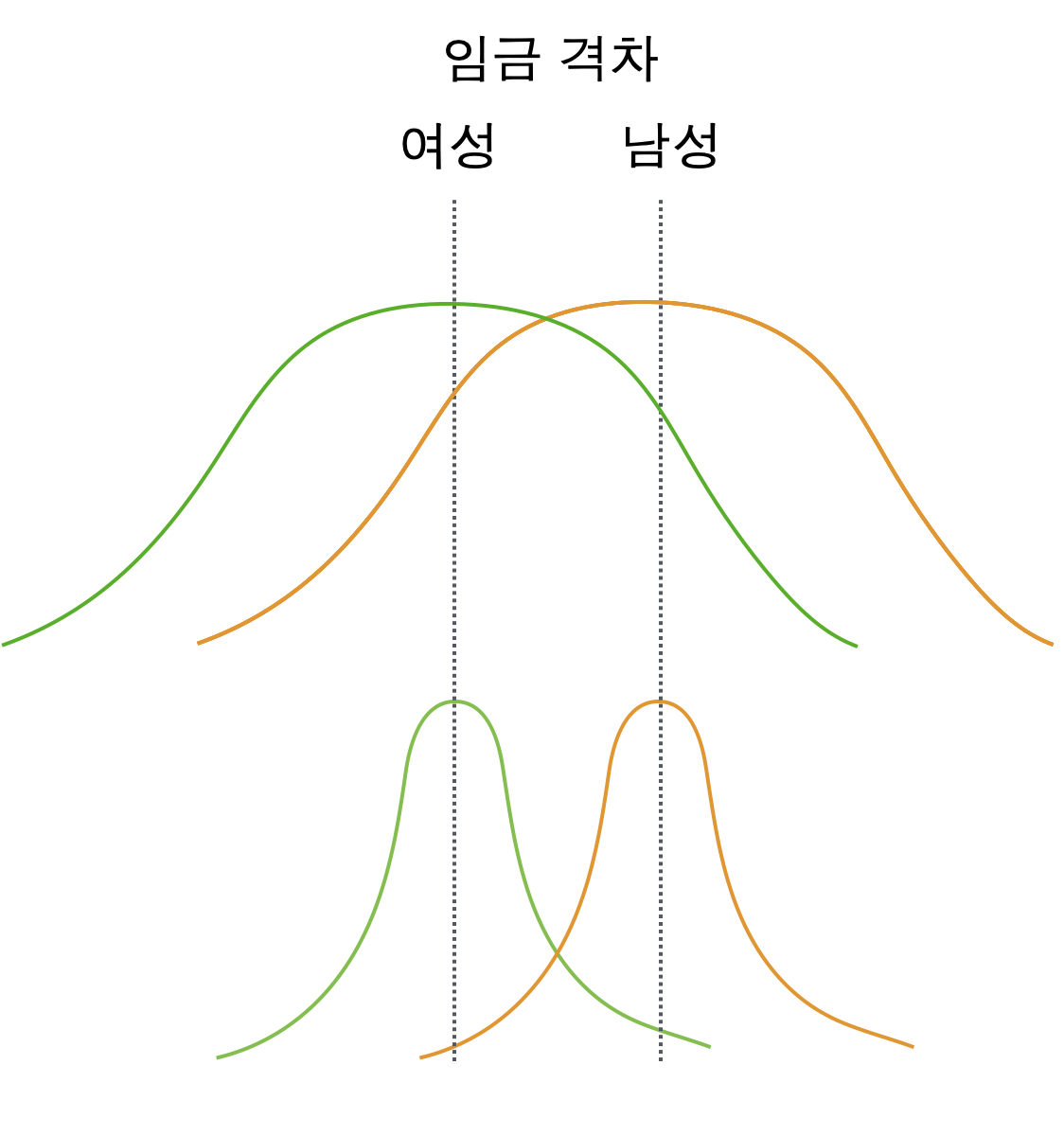
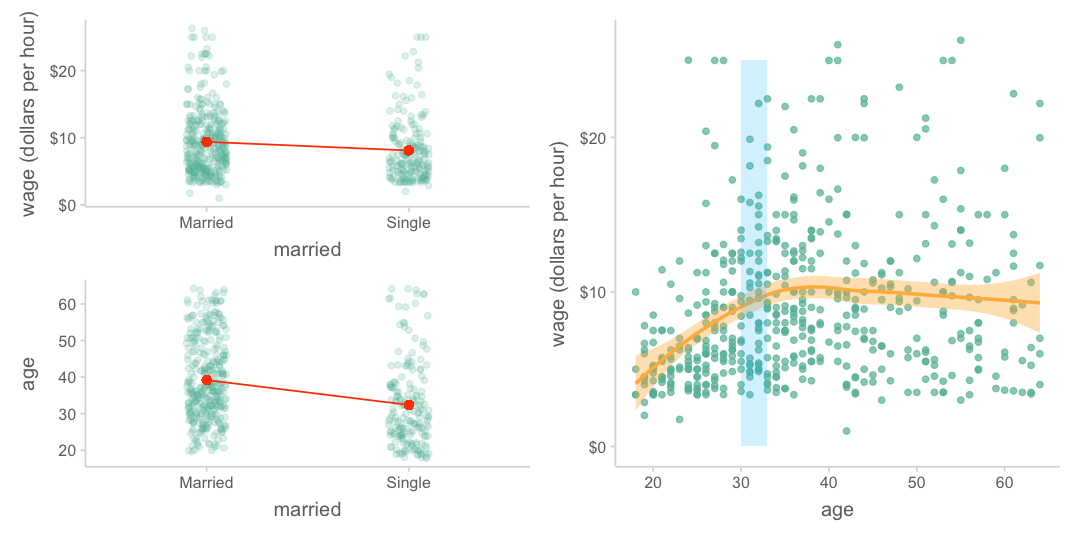
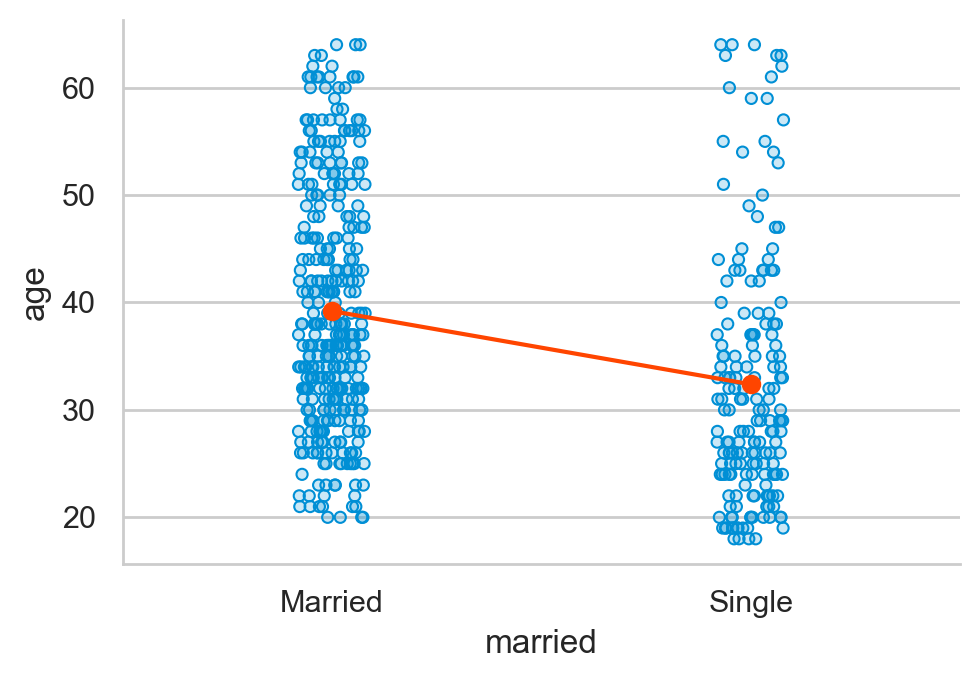
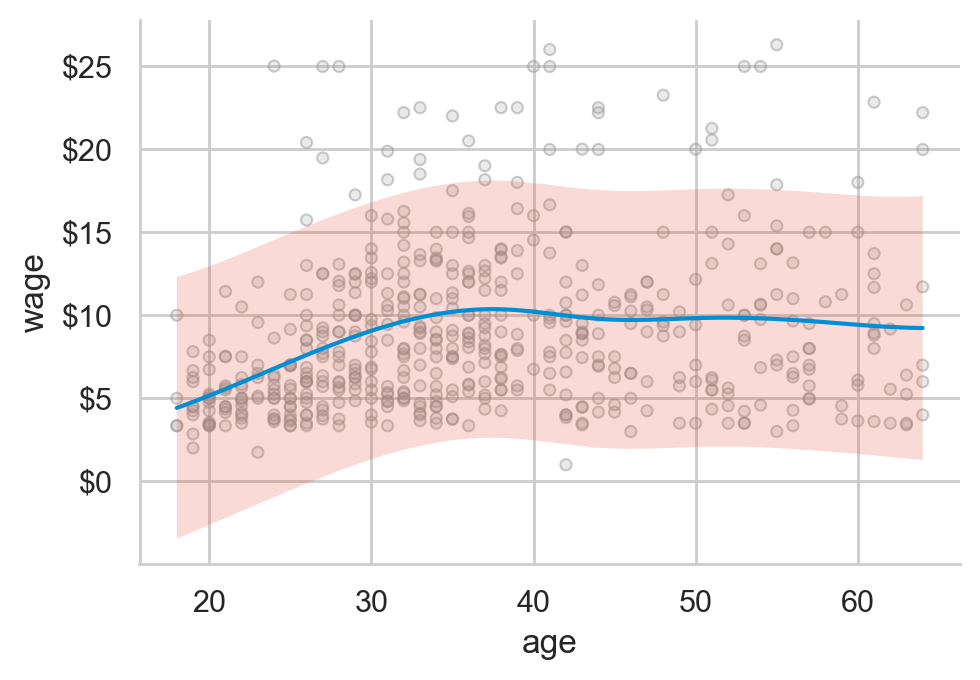
미혼자에 대한 임금 차별이 있는가? 차별이 의미하는 바는 무엇인가? 연령을 고려한 후에도 기혼자의 임금은 미혼자보다 높은가?
여전히 높다면, 연령을 고려한 후 혹은 연령을 조정한 후(adjusted for age)의 차이는 얼마라고 봐야하는가?
연령을 고려한 임금 차이를 조사하는 방법은 무엇이 있겠는가?; 연령별로 나누어 비교?
Data from the 1985 Current Population Survey
연령을 고려한 마라톤 기록?
70세 노인과 20세 청년이 동일하게 2시간 30분의 기록을 세웠다면?
“나이 차이가 큰 두 사람의 기록을 비교하는 것은 공평하지 않아”
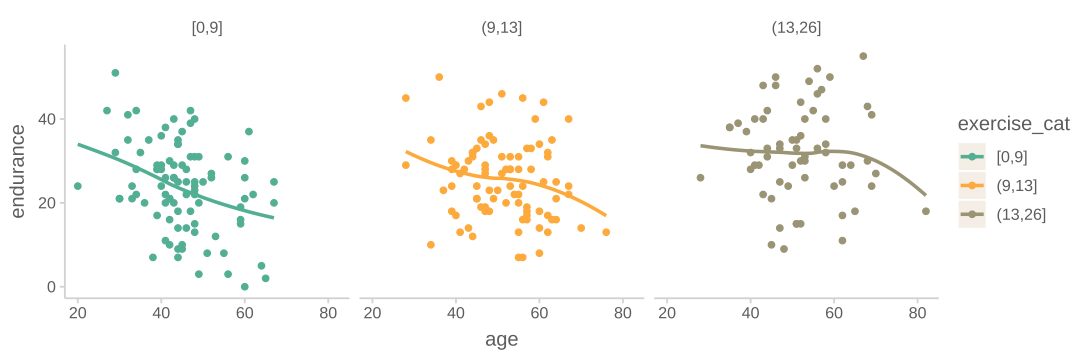
나이를 감안한 마라톤 실력?
다시 말하면, 나이와는 무관한/독립적인 마라톤 능력에 대해 말하고자 함
이는 동일한 나이의 사람들로만 제한해서 마라톤 기록을 비교하는 것이 공평한 능력의 비교라고 말하는 것과 같은 이치임
아래 그림에서 20세라면 보통 2시간 정도, 70세라면 보통 3시간 정도가 전형적인 기록이기 때문에, 이를 고려하여 기록을 조정할 수 있음;
가령, 70세 노인의 기록 2.5시간은 -0.5시간(=3-2.5); 나이로는 설명/예측되지 못하는 정도
20세 청년의 기록 2.5시간은 +0.5시간(=2.5-2); 나이로는 설명/예측되지 못하는 정도
남녀별 연령에 따른 평균 마라톤 기록
Source: https://doi.org/10.1186/2052-1847-6-31
Regression analysis
예측 모형 vs. 인과 모형
인과적 가정없이 예측이 목적인 경우도 있으나 보통 인과적 연관성을 파악하는 것이 목적임
회귀 분석은 전통적으로 “causal inference”에서 중요한 역할을 해왔으나
그 한계가 파악되고 확장되어 앞서 논의한 “causal inference”의 영역이 확립되었음.
예시: 교수의 연봉(salary)이 학위를 받은 후 지난 시간(time since Ph.D.)과 출판물의 수(pubs)에 의해 어떻게 영향을 받는가?
\[salary = b_0 + b_1 \cdot time + b_2 \cdot pubs + \epsilon, ~~ \epsilon \perp\!\!\!\perp time, pubs\]
Source: Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences (3rd ed.)
Intercept 43082.39
time 982.87
pubs 121.80
dtype: float64
세 모형을 비교하면,
Model 1: \(\widehat{salary} = \$1,224\:time + \$43,659\)
Model 2 : \(\widehat{salary} = \$336\:pubs + \$46,357\)
Model 3: \(\widehat{salary} = \$983\:time + \$122\:pubs + \$43,082\)
연차(time)의 효과는 $1,224에서 $984로 낮아졌고,
논문수(pubs)의 효과는 $336에서 $122로 낮아졌음.
교수들의 연차와 그들이 쓴 논문 수는 깊이 연관되어 있으며 (r = 0.66), 두 변수의 redunancy가 각 변수들의 효과를 변화시킴.
두 예측 변수의 산술적 합(\(b_1 \cdot time + b_2 \cdot pubs\))으로 연봉을 예측하므로 각 예측변수의 효과는 (각각 따로 예측할 때에 비해) 수정될 수 밖에 없음.
수학적으로 보면, 각 예측변수의 기울기는 다른 예측변수의 값에 상관없이 일정하므로, 다른 예측변수들을 (임의의 값에) 고정시키는 효과를 가짐
즉, 다른 변수와는 독립적인, 고유한 효과를 추정하게 됨
각 회귀계수를 partial regression coefficient (부분 회귀 계수) 라고 부름.
부분 회귀 계수의 첫번째 해석:
만약 논문 수가 일정할 때, 예를 들어 10편의 논문을 쓴 경우만 봤을 때, 연차가 1년 늘 때마다 연봉은 $984 증가함; 평면(2차원)의 선형모형을 가정했기에 이 관계는 논문 수에 상관없음.
연차가 일정할 때, 예를 들어 연차가 12년차인 경우만 봤을 때, 논문이 1편 늘 때마다 연봉은 $122 증가함; 평면(2차원)의 선형모형을 가정했기에 이 관계는 연차에 상관없음.
이는 다른 변수를 고려 (통제, controlling for) 했을 때 혹은 다른 변수의 효과를 제거 (partial out) 했을 때, 각 변수의 고유한 효과를 의미함; holding constant, controlling for, partialing out, adjusted for, residualizing
뒤집어 말하면, 연차만 고려했을때 연차가 1년 늘면 $1,224 연봉이 증가하는 효과는 연차가 늘 때 함께 늘어나는 논문 수의 효과가 함께 섞여 나온 효과라고 말할 수 있음.
이는 인과관계에 있는 변수들의 진정한 효과를 찾는 것이 얼마나 어려운지를 보여줌
부분 회귀 계수에 대한 두번째 해석
다른 변수들이 partial out 된 후의 효과.
실제로 $122는 “연차로 (선형적으로) 예측/설명되지 않는” 논문수(즉, 잔차)로 “연차로 예측/설명되지 않는” 연봉(즉, 잔차)을 예측할 때의 기울기; 아래 그림에서 보라색으로 예측되는 빨간색 부분
Direct and Indirect Effects
만약, 다음과 같은 인과모형을 세운다면,
연차가 연봉에 미치는 효과가 두 경로로 나뉘어지고,
연차 \(\rightarrow\) 연봉: 직접효과 $983
연차 \(\rightarrow\) 논문 \(\rightarrow\) 연봉: 간접효과 1.98 x $122 = $241.56
두 효과를 더하면: $983 + $241.56 = $1224.56 = 논문수를 고려하지 않았을 때 연차의 효과
즉, 연차가 1년 늘때 연봉이 $1224 증가하는 것은 연차 자체의 효과($983)와 논문의 증가에 따른 효과($241)가 합쳐져 나온 결과라고 말할 수 있음.
이 때, 논문 수를 통한 효과는 연차가 연봉에 미치는 하나의 기제(mechanism)이라고 볼 수 있음.
Strength of Associations
연차와 논문 수로 연봉을 예측했을 때의 \(R^2 = 0.53\)
즉, 연차와 논문 수로 연봉의 변량의 53%를 설명할 수 있음
혹은 \(R = r(Y, \hat{Y}) = \sqrt{0.53} = 0.73\)
반면, 각 변수와 연봉 간의 고유한 상관관계를 측정하고자 한다면 partial/semi-partial correlation을 고려(아래 테이블)
논문 수와는 독립적인 연차와 연봉 간의 부분상관계수(partial correlation) \(pr = 0.53\)
그 제곱 \(pr^2 = 0.28\); 28%의 변량을 설명
연차와는 독립적인 논문 수와 연봉 간의 부분상관계수(partial correlation) \(pr = 0.23\)
그 제곱 \(pr^2 = 0.05\); 5%의 변량을 설명
semi-partial correlation 조금 다른 의미
\(r\)(simple)
\(pr\)(partial)
\(sr\)(semi-partial)
time
0.71
0.53
0.43
pubs
0.59
0.23
0.16
\(r^2\)
\(pr^2\)
\(sr^2\)
time
0.50
0.28
0.18
pubs
0.35
0.05
0.03
직접 효과(direct effect)가 거의 0인 경우
만약, 예를 들어 연차의 효과 $1224이 논문수를 고려했을 때 줄어든($983) 수준을 훨씬 넘어 통계적으로 유의하지 않을 정도로 0에 가까워진다면(즉, 모집단에서는 사실상 0일 가능성이 있음), 연차의 효과는 모두 논문의 효과를 거쳐 나타나는 것이라고 말할 수 있음(직접 효과 = 0). 다시 말하면, 연차 자체는 연봉에 영향을 주지 않음; 완전 매개 (fully mediate)한다고도 표현함.
Spurious Relationships
반대로, 만약 다음과 같이 연차를 고려했을 때 논문수(pubs)의 효과가 거의 사라진다면,
논문수(pubs)와 연봉(salary)의 관계는 spurious(가짜)한 관계라고 잠정적으로 말할 수 있음.
연차를 논문수와 연봉의 common cause 라고 말하며, confounding이 되어 논문수와 연봉의 인과관계는 실제로 없을 수 있음을 암시함.
즉, 논문수가 연봉에 영향을 주는 것처럼 보이는(연관성) 이유는 연차로 인해 모두 증가되어 나타나는 착시현상임.
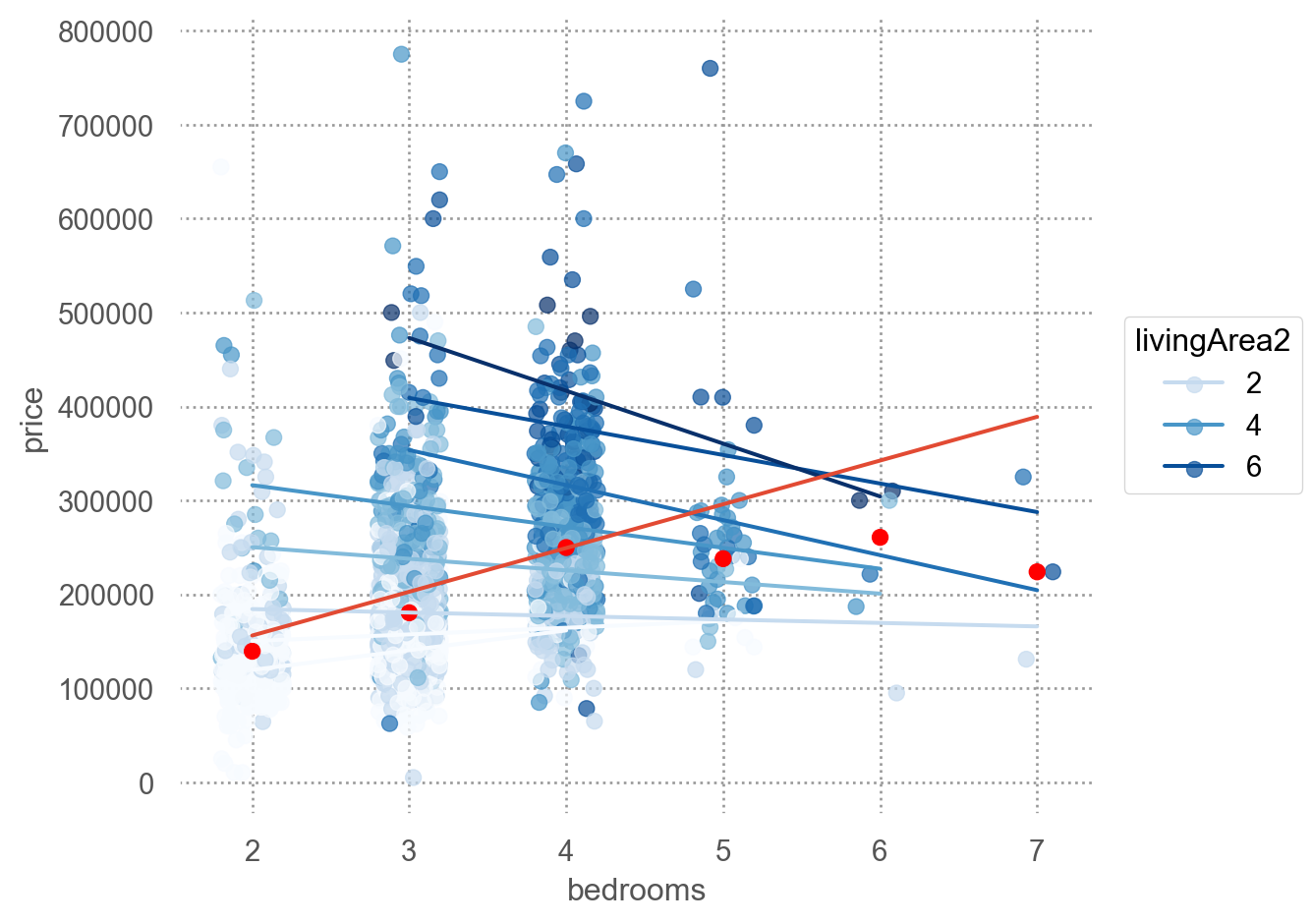
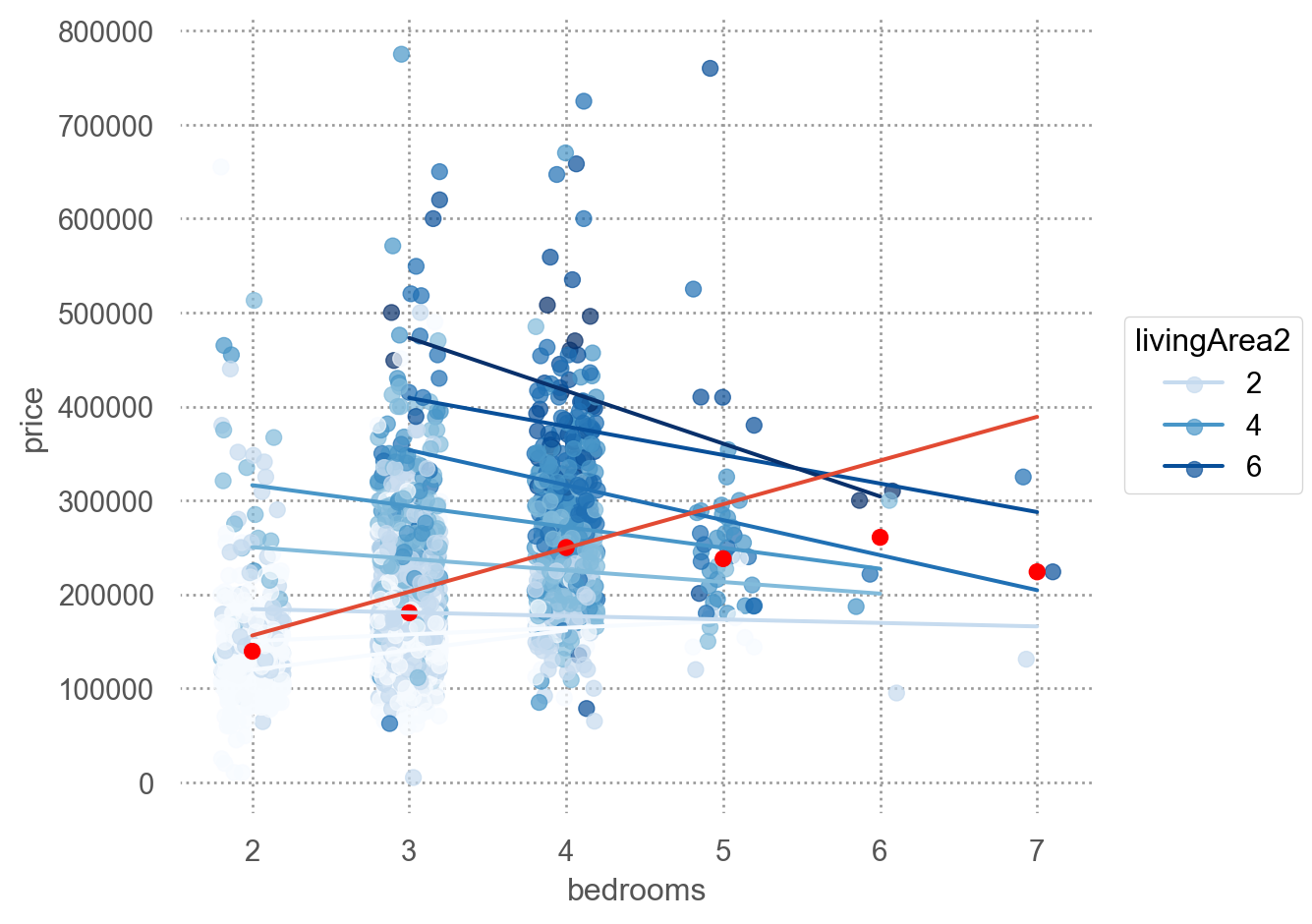
from statsmodels.formula.api import olshouses = sm.datasets.get_rdataset("SaratogaHouses", "mosaicData").dataprint(houses.head(3))
price lotSize age landValue livingArea pctCollege bedrooms \
0 132500 0.09 42 50000 906 35 2
1 181115 0.92 0 22300 1953 51 3
2 109000 0.19 133 7300 1944 51 4
fireplaces bathrooms rooms heating fuel sewer \
0 1 1.00 5 electric electric septic
1 0 2.50 6 hot water/steam gas septic
2 1 1.00 8 hot water/steam gas public/commercial
waterfront newConstruction centralAir
0 No No No
1 No No No
2 No No No
linear model
mod = ols("price ~ livingArea + bedrooms", data=houses).fit()mod.summary()